BODS Designer
Module
Objectives
After
completing this unit, you should be able to understand about:
–BODS tool Menu
–Tool Palates
–Different
objects of BODS
Introduction
•The Data
Integrator Designer provides a graphical user interface (GUI) development
environment in which you defined at a application logic to extract, transform,
and load data from data bases and applications into a data-ware house used for
analytic and on-demand queries.
•You can also
use the Designer to define logical paths for processing message-based queries
and transactions from Web-based, front office, and back-office applications
Logging
in to the Designer
•When we log in
to the Data Integrator Designer, we are actually logging into the database we
defined for the Data Integrator repository.
•Data Integrator
repositories can reside on Oracle, Microsoft SQL Server, Informix, IBM DB2,
Sybase ASE.


•We must
configure a local repository to log into Data Integrator. Typically, we create
a repository during installation. However, we can create a repository at any
time using the Data Integrator Repository Manager.
•Each repository
must be associated with at least one Job Server, which is the process that
starts jobs.
•When running a
job from a repository, we select one of the associated repositories.
•We can link any
number of repositories to a single Job Server. The same Job Server can run jobs
stored on multiple repositories.
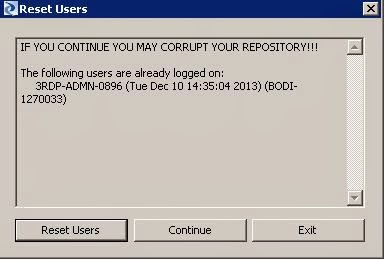
•Occasionally,
more than one person may attempt to log in to a single repository. If this
happens, the Reset Users window appears, listing the users and the time they
logged in to the repository

Designer user interface
Data Integrator objects
- All ―entities we
define, edit, or work with in Data Integrator Designer are called objects.
- The local object
library shows objects such as source and target metadata, system
functions, projects, and jobs.
- Data Integrator has two
types of objects:
–Reusable objects
–Single-use objects
Reusable objects
- After
we define and save a reusable object, Data Integrator stores the
definition in the local repository.
- We
can then re-use the definition as often as necessary by creating calls to
the definition in the local object library.
- The
object library contains object definitions. When we drag and drop an
object from the object library, we are really creating a new reference (or
call) to the existing object definition.
- Single-use
objects
- Some
objects are defined only within the context of a single job or data flow,
for example scripts and specific transform definitions.
Designer window
•The Data
Integrator Designer user interface consists of a single application window and
several embedded supporting windows.


Menu bar
•Menu bar
contains a brief description of the Designer’s menus:
Project
menu
Edit menu
View menu
Tools menu
Debug menu
Validation
menu
Window
menu
Help menu
Toolbar
•In addition to
many of the standard Windows tools, Data Integrator provides
application-specific tools, including:


Project
area
The project area
provides a hierarchical view of the objects used in each project. Tabs on the
bottom of the project area support different tasks. Tabs include:


As we drill down
into objects in the Designer workspace, the window highlights our location
within the project hierarchy.
Tool
palette

 •The tool palette is a separate window that allows us to create
new objects in the workspace. The icons are disabled when they are not allowed
to be added to the diagram open in the workspace.
•The tool palette is a separate window that allows us to create
new objects in the workspace. The icons are disabled when they are not allowed
to be added to the diagram open in the workspace.
•The icons in
the tool palette allows us to create new objects in the workspace. The icons
are disabled when they are not allowed to be added to the diagram open in the
workspace.
•When we create
an object from the tool palette, we are creating a new definition of an object.
If a new object is reusable, it will be automatically available in the object
library after we create it.
Work space
•When we open or
select a job or any flow within a job hierarchy, the workspace becomes
―active with our selection.
•The workspace
provides a place to manipulate system objects and graphically assemble data
movement processes.
•Workspace
diagram is a visual representation of an entire data movement application or
some part of a data movement application.
•We specify the
flow of data through jobs and work flows by connecting objects in the workspace
from left to right in the order we want the data to
Describing
objects
we can use
descriptions to add comments about objects. We can use annotations to explain a
job, work flow, or data flow. We can view object descriptions and annotations
in the workspace.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
•When we drill
into an object in the project area or work-space, a view of the object’s
definition opens in the work space area. The view is marked by a tab at the
bottom of the work space area.
•These views use
system resources. If we have a large number of open views, we might notice a
decline in performance.
•The local
object library provides access to reusable objects. These objects include
built-in system objects, such as transforms, and the objects we build and save,
such as datastores, jobs, dataflows, and workflows.
•The local
object library is a window in to our local Data Integrator repository and
eliminates the need to access the repository directly.
•Updates to the
repository occur through normal Data Integrator operation. Saving the objects
we create, adds them to the repository. You can access saved objects through
the local object library.
Local object library
Local object library


Object Editors
•The editor displays the input and output schemes for the object and a panel below them lists options set for the object. If there are many options , they are grouped in tabs in the editor.
•The editor displays the input and output schemes for the object and a panel below them lists options set for the object. If there are many options , they are grouped in tabs in the editor.
{kind=link}
Object
editors
In an editor, we can:
•Undo or redo previous actions performed in the window
•Find a string in the editor
•Drag-and-drop column names from the input schema into relevant option boxes
•Use colors to identify strings and comments in text boxes where we can edit expressions (keywords appear blue; strings are enclosed in quotes and appear pink; comments begin with a pound sign and appear green)
•We cannot add comments to a mapping clause in a Query transform.
•We can create reusable objects from the object library or by using the tool palette. After we create an object, we can work with the object, editing its definition and adding calls to other objects.
•We define an object using other objects. For example, if we click the name of a batch data flow, a new workspace opens for we to assemble sources, targets, and transforms that make up the actual flow.
Working with objects
•Objects dragged into the workspace must obey the hierarchy logic.
•For example,
–We can drag a data flow into a job, but we cannot drag a work-flow into a data-flow.
–We can change the name of an object from the workspace or the objectlibrary.
–We can also create a copy of an existing object. we cannot change the names of
built-in objects. Data Integrator makes a copy of the top-level object (but not of
objects that it calls) and gives it a new name, which we can edit.
–We can view (and, in some cases, change) an object’s properties through its property page.
–We can use descriptions to document objects. we can see descriptions on workspace diagrams. Therefore, descriptions area convenient way to add comments to workspace objects.
–A description is associated with a particular object. When we import or export that repository object, we also import or export its description.
In an editor, we can:
•Undo or redo previous actions performed in the window
•Find a string in the editor
•Drag-and-drop column names from the input schema into relevant option boxes
•Use colors to identify strings and comments in text boxes where we can edit expressions (keywords appear blue; strings are enclosed in quotes and appear pink; comments begin with a pound sign and appear green)
•We cannot add comments to a mapping clause in a Query transform.
•We can create reusable objects from the object library or by using the tool palette. After we create an object, we can work with the object, editing its definition and adding calls to other objects.
•We define an object using other objects. For example, if we click the name of a batch data flow, a new workspace opens for we to assemble sources, targets, and transforms that make up the actual flow.
Working with objects
•Objects dragged into the workspace must obey the hierarchy logic.
•For example,
–We can drag a data flow into a job, but we cannot drag a work-flow into a data-flow.
–We can change the name of an object from the workspace or the objectlibrary.
–We can also create a copy of an existing object. we cannot change the names of
built-in objects. Data Integrator makes a copy of the top-level object (but not of
objects that it calls) and gives it a new name, which we can edit.
–We can view (and, in some cases, change) an object’s properties through its property page.
–We can use descriptions to document objects. we can see descriptions on workspace diagrams. Therefore, descriptions area convenient way to add comments to workspace objects.
–A description is associated with a particular object. When we import or export that repository object, we also import or export its description.
Working with objects
•Annotations describe a flow, part of a flow, or a diagram in a workspace. An annotation is associated with the job, work flow, or data flow where it appears. When we import or export that job, work flow, or data flow, we import or export associated annotations.
•We can add, edit, and delete text directly on the annotation. In addition, we can resize and move the annotation by clicking and dragging. we can add any number of annotations to a diagram.
•We cannot hide an notations that we have added to the workspace. However, we can move them out of the way or delete them.
•―Saving an object in Data Integrator means storing the language that describes the object to the repository. We can save reusable objects. Single use objects are saved only as part of the definition of there usable object that calls them.
•We can choose to save changes to there usable object currently open in the workspace. When we save the object, the object properties, the definitions of any single use objects it calls, and any calls to other reusable objects are recorded in the repository. The content of the included reusable objects is not saved; only the call is saved.
•Data Integrator stores the description even if the object is not complete or contains an error (does not validate).
•Data Integrator also prompts us to save all objects that have changes when we execute a job and when we exit the Designer.


good blog
ReplyDeletesap bods course online training in Hyderabad
sap bods course online training in usa
sap bods course online training in canada
sap bods course online training in australia
Admiring the time and effort you put into your blog and detailed information you offer!..
ReplyDeleteDefinition of SAP